Real Case: Spam Detection Model for Fintech
Spam Detection Model for Fintech Platform
By: Jorge Luis Solis Servelion
Data Scientist and Financial Analyst
San Francisco, 2024
Jupyter notebook and dataset for this analysis can be found here: Portfolio
Introduction
The purpose of this analysis is to leverage advanced machine learning and natural language processing (NLP) techniques to build an efficient spam detection system. We utilize a combination of traditional machine learning models and state-of-the-art deep learning models, specifically BERT (Bidirectional Encoder Representations from Transformers), to classify text as spam or not spam.
Business Impact
Implementing an effective spam detection system will have several positive impacts on our platform:
- Enhanced User Experience: By filtering out spam, users will have a more enjoyable and productive experience, leading to increased engagement and retention.
- Improved Content Quality: Ensuring that only relevant and valuable content is displayed will maintain the platform’s reputation and attract more users.
- Operational Efficiency: Automating spam detection reduces the need for manual moderation, saving time and resources.
Technology Stack
- Programming Language: Python
- Libraries: Pandas, NumPy, NLTK, Gensim, Scikit-learn, Transformers (Hugging Face), Seaborn, Matplotlib, Flask, Joblib
- Platforms: AWS (Ubuntu instance), Jupyter Notebook
Part I: Imports and Data Check
Importing Libraries
# Importing libraries
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import nltk
import re
import string
import os
import csv
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from collections import Counter
import json
from afinn import Afinn
from sklearn.feature_extraction.text import TfidfVectorizer
import gensim
from gensim import corpora
import pyLDAvis.gensim_models
from nltk.sentiment.vader import SentimentIntensityAnalyzer
from wordcloud import WordCloud
from nrclex import NRCLex
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
import networkx as nx
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix, roc_auc_score
from imblearn.over_sampling import SMOTE
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV, cross_val_score
from flask import Flask, request, render_template
import joblib
from collections.abc import Sequence
from scipy.sparse import hstack
from sklearn.cluster import KMeans
from sklearn.ensemble import IsolationForest
from sklearn.semi_supervised import LabelSpreading
nltk.download('vader_lexicon')
nltk.download('punkt')
nltk.download('stopwords')
Data Import
# Reading the file
file = './feed_messages(reformatted3).csv'
feed_messages_df = pd.read_csv(
filepath_or_buffer=file,
delimiter='|',
encoding='utf-8',
quoting=csv.QUOTE_NONE,
on_bad_lines='skip'
)
Part II: Data Preparation - Base Modeling
Data Cleaning
# Change the column types
feed_messages_df['feed_type'] = feed_messages_df['feed_type'].astype(str)
feed_messages_df['created_utc_timestamp'] = pd.to_datetime(feed_messages_df['created_utc_timestamp'], errors='coerce')
feed_messages_df['dislikes'] = feed_messages_df['dislikes'].astype('Int64')
feed_messages_df['likes'] = feed_messages_df['likes'].astype('Int64')
feed_messages_df['weighted_time_stamp'] = pd.to_datetime(feed_messages_df['weighted_time_stamp'])
feed_messages_df['user_views'] = feed_messages_df['user_views'].astype('Int64')
feed_messages_df['views'] = feed_messages_df['views'].astype('Int64')
# Dropping the columns with no added value
feed_messages_df = feed_messages_df.drop(columns=['user_id', 'host_name', 'weighted_time_stamp', 'timestamp_utc'])
feed_messages_df = feed_messages_df.dropna(subset=['id', 'metadata'])
Data Transformation
# Create a dictionary for the feed_type mappings
feed_type_mapping = {
'2.0': 'votingEvent',
'13.0': 'articles',
'8.0': 'updatedVotingEvent',
'6.0': 'marketThoughts',
'11.0': 'articles',
'7.0': 'votingEventWithImages',
'10.0': 'articles',
'12.0': 'articles',
'9.0': 'updatedVotingEventWithImages'
}
# Map the feed_type column to its corresponding labels
feed_messages_df['feed_type_label'] = feed_messages_df['feed_type'].map(feed_type_mapping)
Expanding Metadata
# Convert all entries in 'metadata' to strings, replacing None and other non-string entries
feed_messages_df['metadata'] = feed_messages_df['metadata'].apply(lambda x: '{}' if x is None else str(x))
# Function to clean the JSON string in the metadata column
def clean_metadata(json_str):
if isinstance(json_str, str):
if json_str.startswith('"') and json_str.endswith('"'):
json_str = json_str[1:-1]
json_str = json_str.replace('\\"', '"')
return json_str
# Apply the function to the metadata column
feed_messages_df['metadata'] = feed_messages_df['metadata'].apply(clean_metadata)
# Convert the cleaned JSON strings in the metadata column to new columns
def safe_json_loads(json_str):
try:
return json.loads(json_str)
except json.JSONDecodeError:
return {}
metadata_df = feed_messages_df['metadata'].apply(safe_json_loads).apply(pd.Series)
# Merge the new columns with the original dataframe
feed_messages_expanded_df = pd.concat([feed_messages_df, metadata_df], axis=1)
Part III: Exploratory Data Analysis (EDA)
Token Frequency Analysis
# Filter the data
votingEventdf = feed_messages_expanded_df[
(feed_messages_expanded_df['Comments'].notnull()) &
(feed_messages_expanded_df['feed_type_label'].isin(['votingEvent', 'updatedVotingEvent', 'votingEventWithImages', 'updatedVotingEventWithImages']))
]
# Rename the column 'Comments' to 'text'
votingEventdf.rename(columns={'Comments': 'text'}, inplace=True)
# Define a function to remove special characters
def remove_special_characters(text):
text = text.lower()
pattern = r'[^\w\s]'
cleaned_text = re.sub(pattern, '', text)
return cleaned_text
stop_words = set(stopwords.words('english'))
additional_stop_words = {'liking', 'pick', 'quickadded'}
# Function to remove stop words and additional words
def remove_stop_words_and_additional(text_tokens):
return [word for word in text_tokens if word.lower() not in stop_words and word.lower() not in additional_stop_words]
# Removing special characters
votingEventdf['text'] = votingEventdf['text'].astype(str)
votingEventdf['text_cleaned'] = votingEventdf['text'].apply(remove_special_characters)
votingEventdf['text_tokenized'] = votingEventdf['text_cleaned'].apply(word_tokenize)
votingEventdf['text_no_stop'] = votingEventdf['text_tokenized'].apply(remove_stop_words_and_additional)
# Flatten the list of words into a single list
all_words = [word for tokens in votingEventdf['text_no_stop'] for word in tokens]
# Counting frequencies
word_freq = Counter(all_words)
common_words = word_freq.most_common()
# Convert to DataFrame for easier plotting
freq_df = pd.DataFrame(common_words, columns=['word', 'count'])
# Filtering to get words with more than 100 occurrences
freq_df = freq_df[freq_df['count'] > 100]
top_30_words = freq_df.head(30)
# Plotting the token frequencies
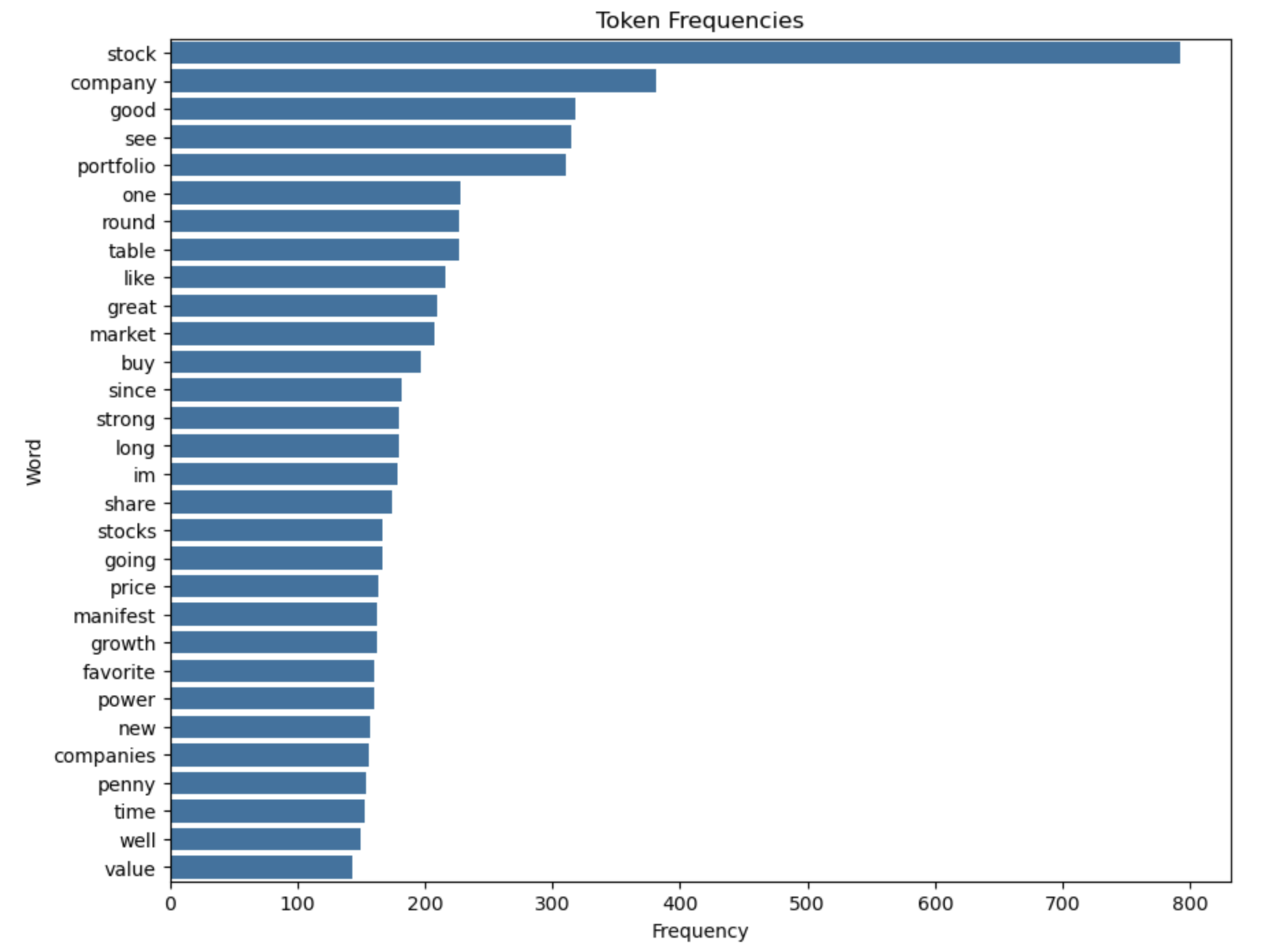
plt.figure(figsize=(10,8))
sns.barplot(x='count', y='word', data=top_30_words.sort_values(by='count', ascending=False))
plt.xlabel('Frequency')
plt.ylabel('Word')
plt.title('Token Frequencies')
plt.show()
Output:
TF-IDF Analysis
# Rejoining the tokens into strings for TF-IDF calculation
votingEventdf['text_no_stop_joined'] = votingEventdf['text_no_stop'].apply(lambda x: ' '.join(x))
# Calculating TF-IDF
vectorizer = TfidfVectorizer(stop_words='english')
X = vectorizer.fit_transform(votingEventdf['text_no_stop_joined'])
tfidf_df = pd.DataFrame(X.toarray(), columns=vectorizer.get_feature_names_out())
# Sum up the TF-IDF values for each word
tfidf_sum = tfidf_df.sum().reset_index().rename(columns={0: 'tf_idf', 'index': 'word'})
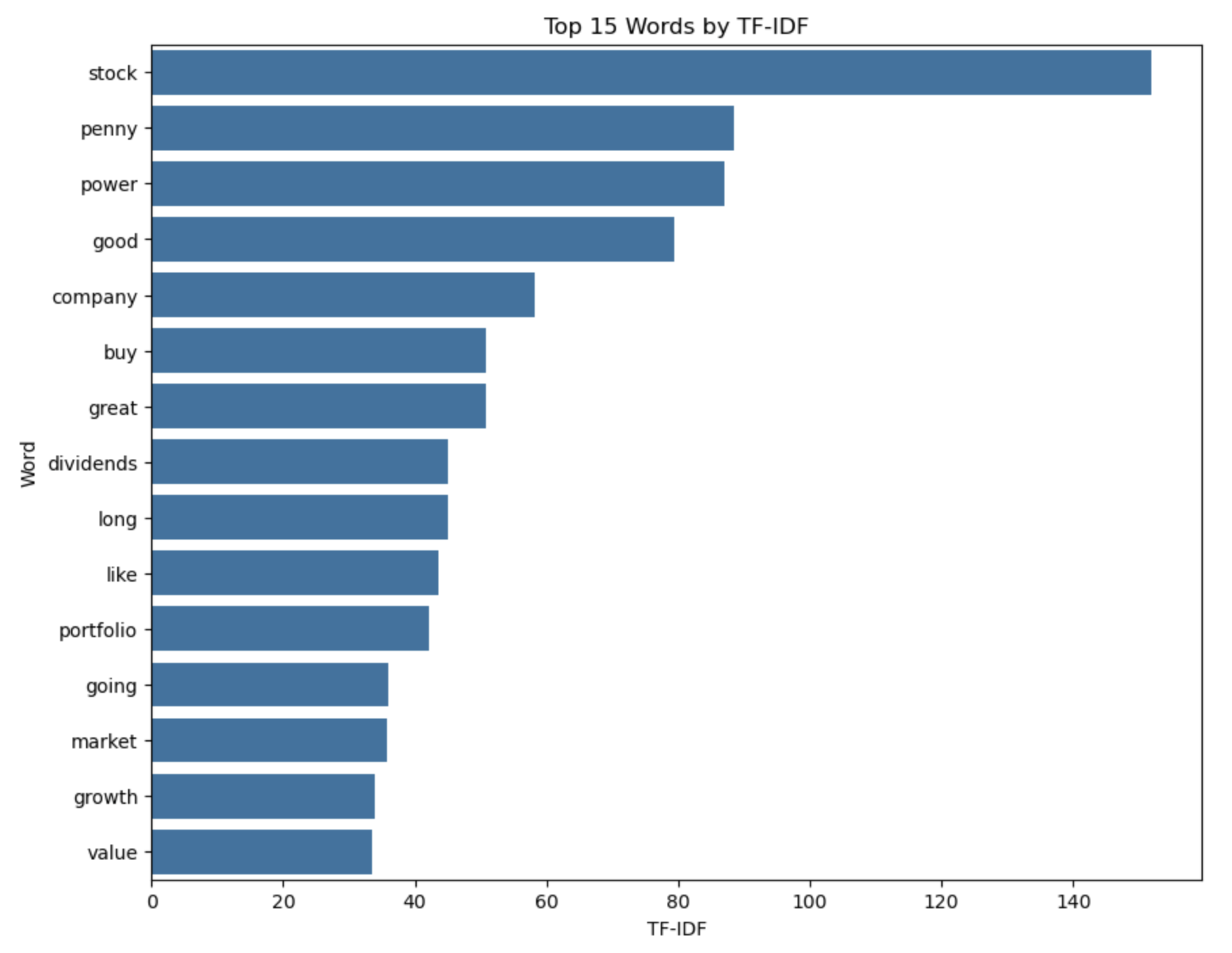
# Plotting
TF-IDF values
tfidf_top_15 = tfidf_sum.sort_values(by='tf_idf', ascending=False).head(15)
plt.figure(figsize=(10,8))
sns.barplot(x='tf_idf', y='word', data=tfidf_top_15)
plt.xlabel('TF-IDF')
plt.ylabel('Word')
plt.title('Top 15 Words by TF-IDF')
plt.show()
Output:
LDA Analysis
# Prepare data for LDA
texts = votingEventdf['text_no_stop'].tolist()
# Create a dictionary and a corpus
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
# Apply LDA
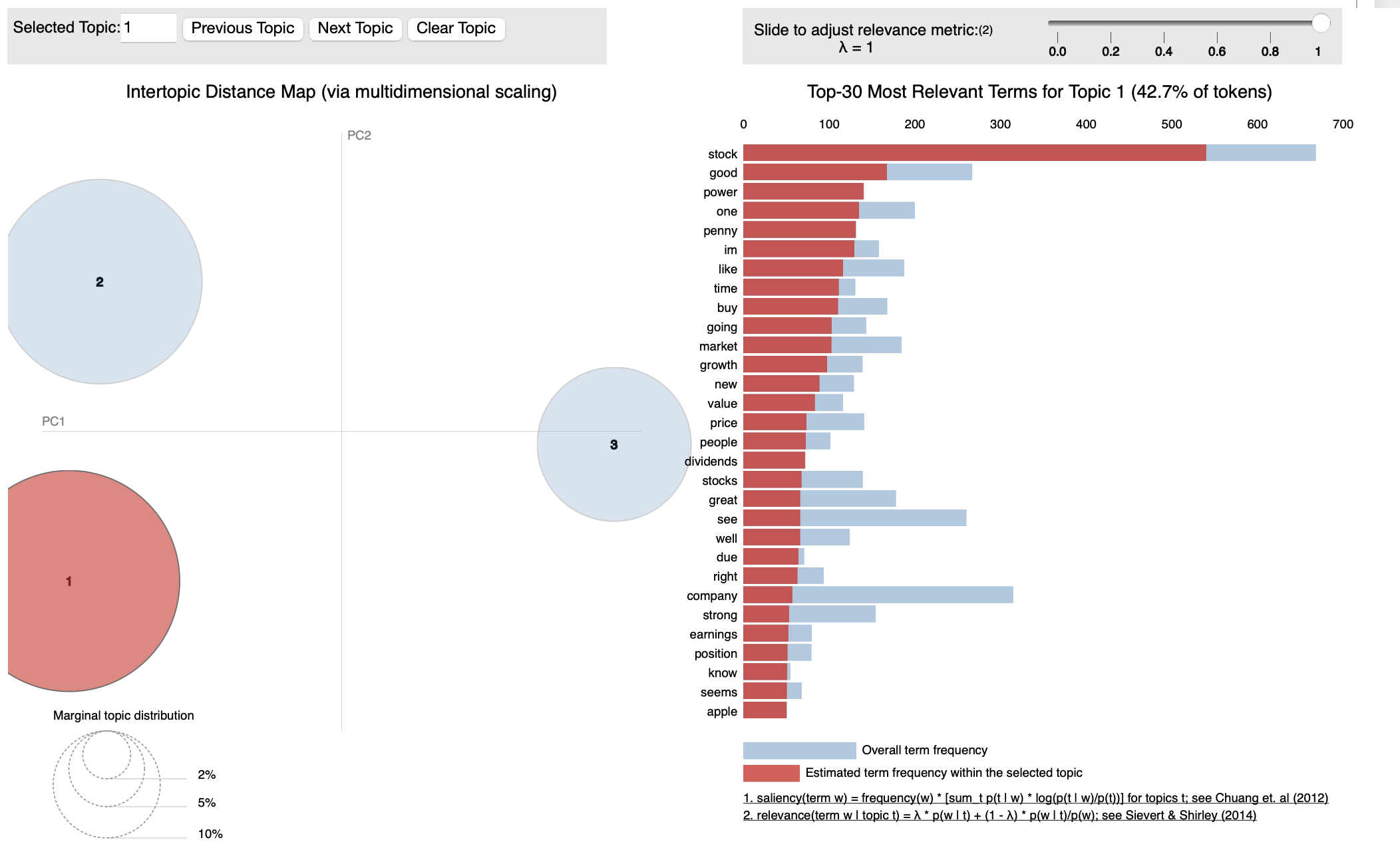
lda_model = gensim.models.LdaModel(corpus, num_topics=3, id2word=dictionary, passes=10, random_state=123)
# Print the topics
for idx, topic in lda_model.print_topics(-1):
print('Topic: {} \nWords: {}'.format(idx, topic))
# Visualize the topics
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim_models.prepare(lda_model, corpus, dictionary)
pyLDAvis.display(vis)
Output:
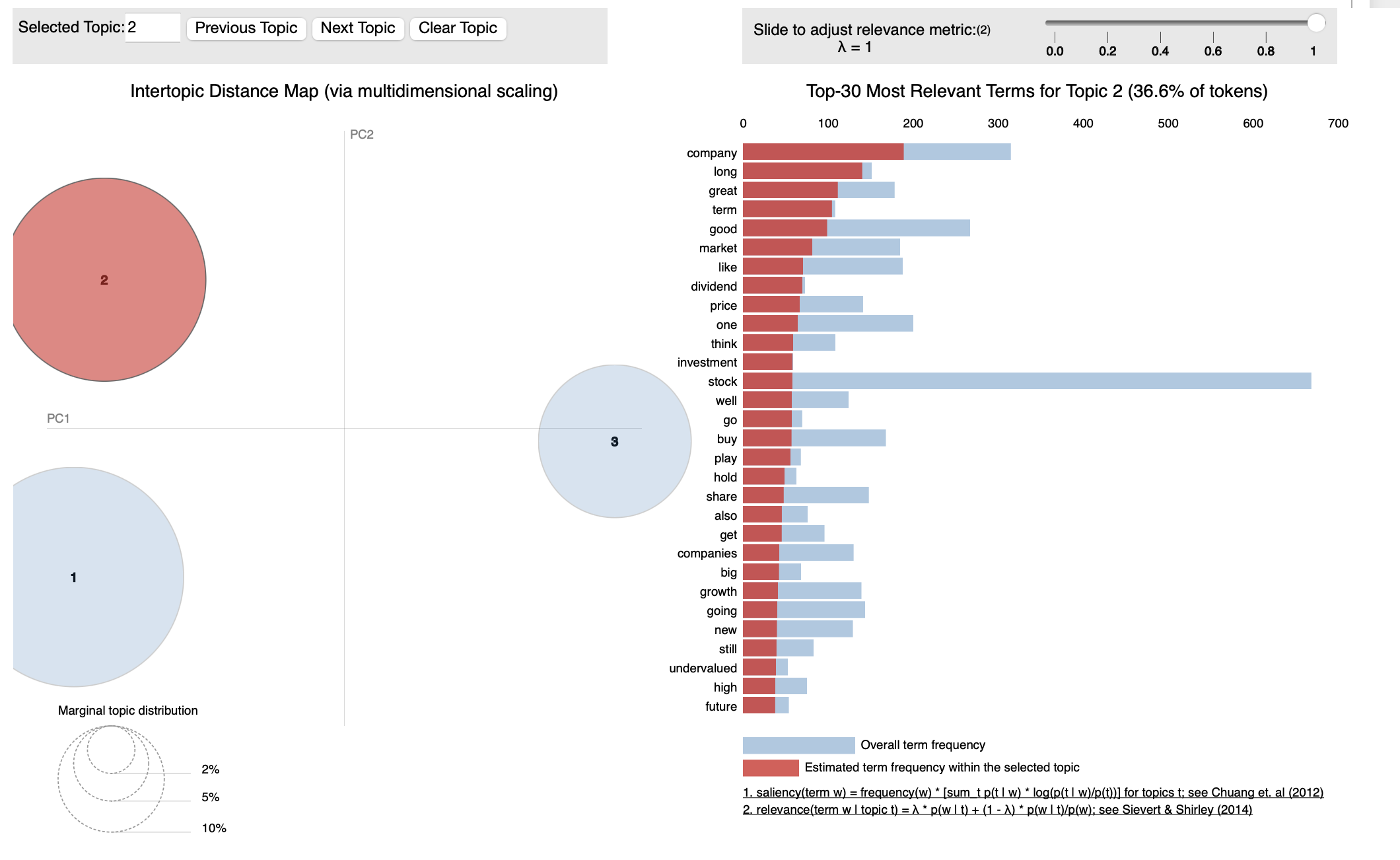
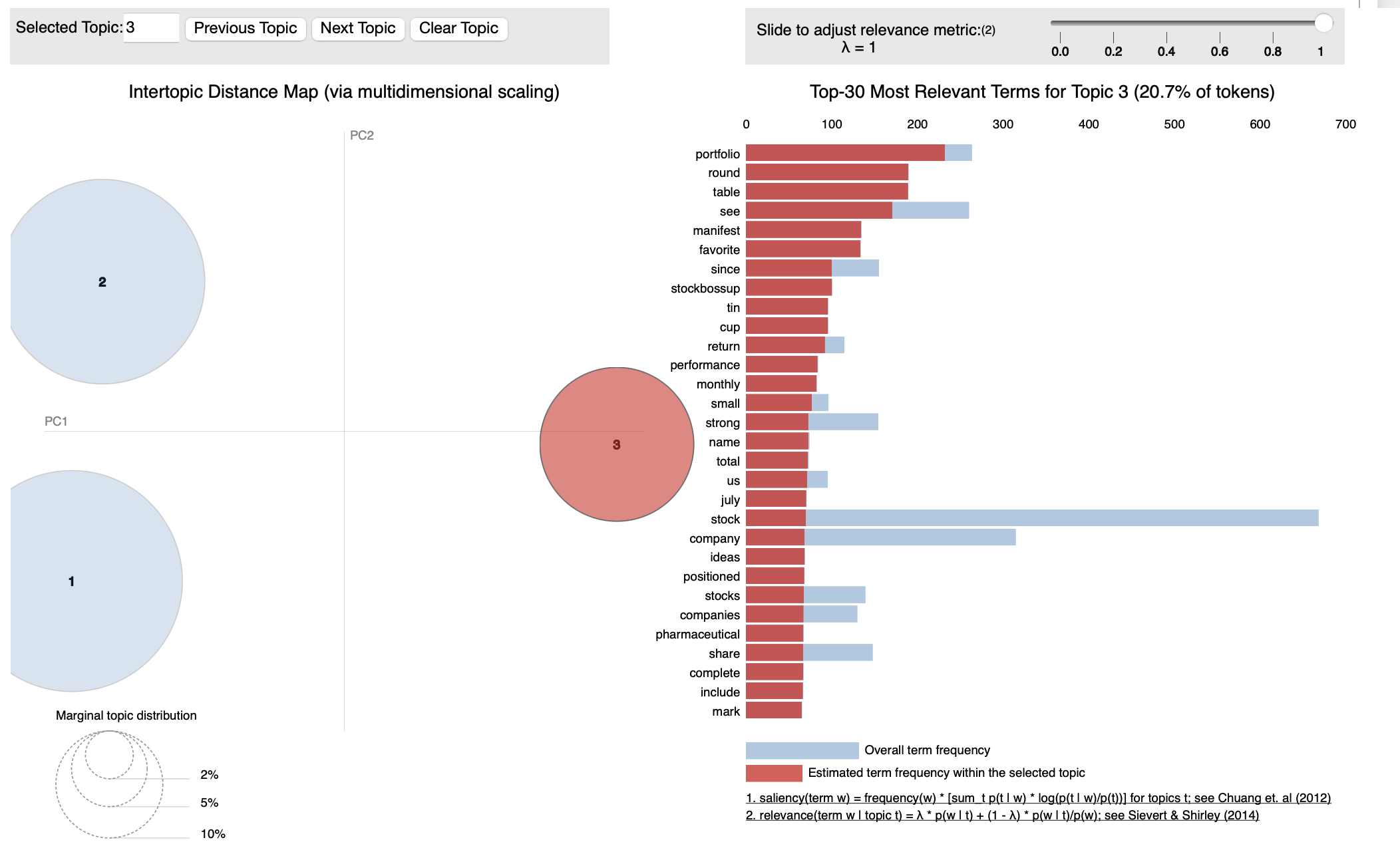
N-Grams Analysis
Copy code
# Function to generate n-grams
def generate_ngrams(text_series, n):
vectorizer = CountVectorizer(ngram_range=(n, n), stop_words='english')
X = vectorizer.fit_transform(text_series)
ngrams = pd.DataFrame(X.toarray(), columns=vectorizer.get_feature_names_out())
return ngrams, vectorizer
# Generate bigrams
bigrams, bigram_vectorizer = generate_ngrams(votingEventdf['text_no_stop_joined'], 2)
# Generate quadrograms
quadrograms, quadrogram_vectorizer = generate_ngrams(votingEventdf['text_no_stop_joined'], 4)
# Convert bigrams to DataFrame with counts
bigram_counts = bigrams.sum().reset_index().rename(columns={0: 'count', 'index': 'bigram'}).sort_values(by='count', ascending=False)
# Convert quadrograms to DataFrame with counts
quadrogram_counts = quadrograms.sum().reset_index().rename(columns={0: 'count', 'index': 'quadrogram'}).sort_values(by='count', ascending=False)
print(bigram_counts.head())
print(quadrogram_counts.head())
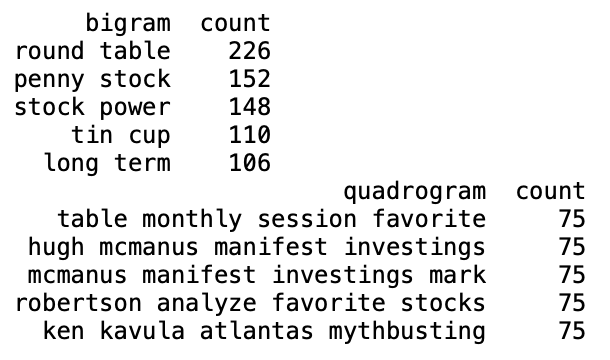
# Function to calculate TF-IDF
def calculate_tfidf(ngrams, vectorizer):
transformer = TfidfTransformer()
tfidf_matrix = transformer.fit_transform(ngrams)
tfidf_df = pd.DataFrame(tfidf_matrix.toarray(), columns=vectorizer.get_feature_names_out())
tfidf_sum = tfidf_df.sum().reset_index().rename(columns={0: 'tf_idf', 'index': 'ngram'}).sort_values(by='tf_idf', ascending=False)
return tfidf_sum
# Calculate TF-IDF for bigrams
bigram_tfidf = calculate_tfidf(bigrams, bigram_vectorizer)
print(bigram_tfidf.head())
# Calculate TF-IDF for quadrograms
quadrogram_tfidf = calculate_tfidf(quadrograms, quadrogram_vectorizer)

Visualize bigram network
def visualize_bigram_network(bigram_counts, min_count=10):
bigrams_separated = bigram_counts['bigram'].str.split(expand=True).rename(columns={0: 'word1', 1: 'word2'})
bigrams_separated['count'] = bigram_counts['count']
bigrams_filtered = bigrams_separated[bigrams_separated['count'] > min_count]
bigram_graph = nx.from_pandas_edgelist(bigrams_filtered, 'word1', 'word2', ['count'])
plt.figure(figsize=(12, 8))
pos = nx.spring_layout(bigram_graph, k=0.15, iterations=20)
nx.draw(bigram_graph, pos, with_labels=True, node_size=30, node_color='skyblue', font_size=10, edge_color='gray')
plt.title('Bigram Network')
plt.show()
visualize_bigram_network(bigram_counts)
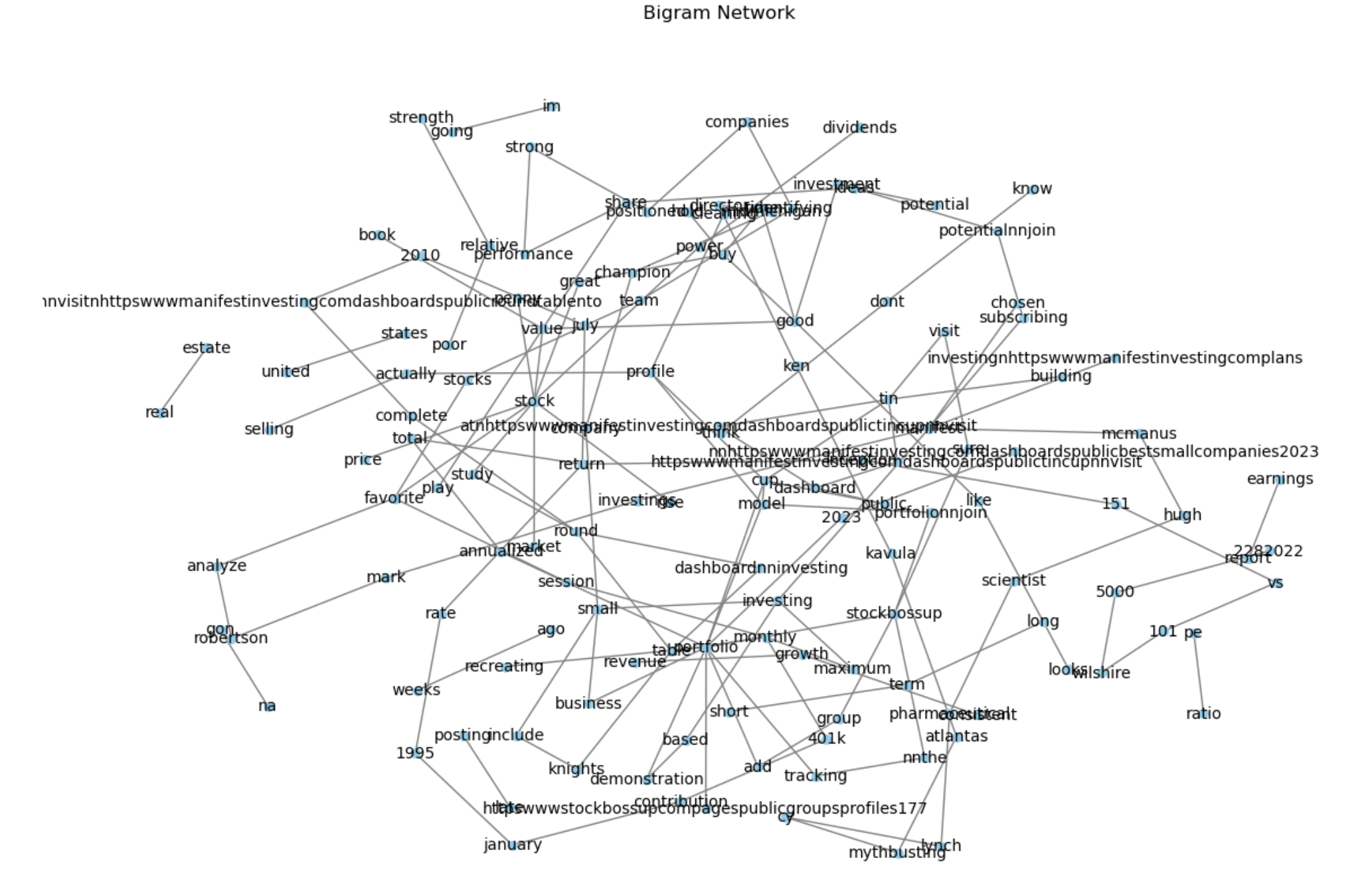
Sentiment Analysis
# Sentiment Analysis
analyzer = SentimentIntensityAnalyzer()
def sentiment_analysis(text):
return analyzer.polarity_scores(text)
votingEventdf['sentiment'] = votingEventdf['text_no_stop_joined'].apply(sentiment_analysis)
# Extract sentiment scores
votingEventdf['compound'] = votingEventdf['sentiment'].apply(lambda x: x['compound'])
votingEventdf['neg'] = votingEventdf['sentiment'].apply(lambda x: x['neg'])
votingEventdf['neu'] = votingEventdf['sentiment'].apply(lambda x: x['neu'])
votingEventdf['pos'] = votingEventdf['sentiment'].apply(lambda x: x['pos'])
# Aggregating the sentiment scores for the entire dataset
sentiment_summary = votingEventdf[['compound', 'neg', 'neu', 'pos']].mean()
print(sentiment_summary)
# Plotting sentiment distributions
plt.figure(figsize=(10, 6))
sns.histplot(votingEventdf['compound'], kde=True, bins=30)
plt.title('Distribution of Compound Sentiment Scores')
plt.xlabel('Compound Sentiment Score')
plt.ylabel('Frequency')
plt.show()
# Analyzing sentiment by feed type
feed_sentiment = votingEventdf.groupby('feed_type_label').agg({
'compound': 'mean',
'neg': 'mean',
'neu': 'mean',
'pos': 'mean'
}).reset_index()
# Most common positive and negative words
# Using VADER sentiment for simplicity, you can adjust to use another sentiment library if preferred
positive_words = [word for word in all_words if analyzer.polarity_scores(word)['compound'] > 0]
negative_words = [word for word in all_words if analyzer.polarity_scores(word)['compound'] < 0]
positive_word_freq = Counter(positive_words).most_common()
negative_word_freq = Counter(negative_words).most_common()
# Convert to DataFrame
positive_freq_df = pd.DataFrame(positive_word_freq, columns=['word', 'count'])
negative_freq_df = pd.DataFrame(negative_word_freq, columns=['word', 'count'])
# Plotting the top 10 positive words
plt.figure(figsize=(10, 8))
sns.barplot(x='count', y='word', data=positive_freq_df.head(10))
plt.title('Top 10 Positive Words')
plt.xlabel('Count')
plt.ylabel('Word')
plt.show()
# Plotting the top 10 negative words
plt.figure(figsize=(10, 8))
sns.barplot(x='count', y='word', data=negative_freq_df.head(10))
plt.title('Top 10 Negative Words')
plt.xlabel('Count')
plt.ylabel('Word')
plt.show()
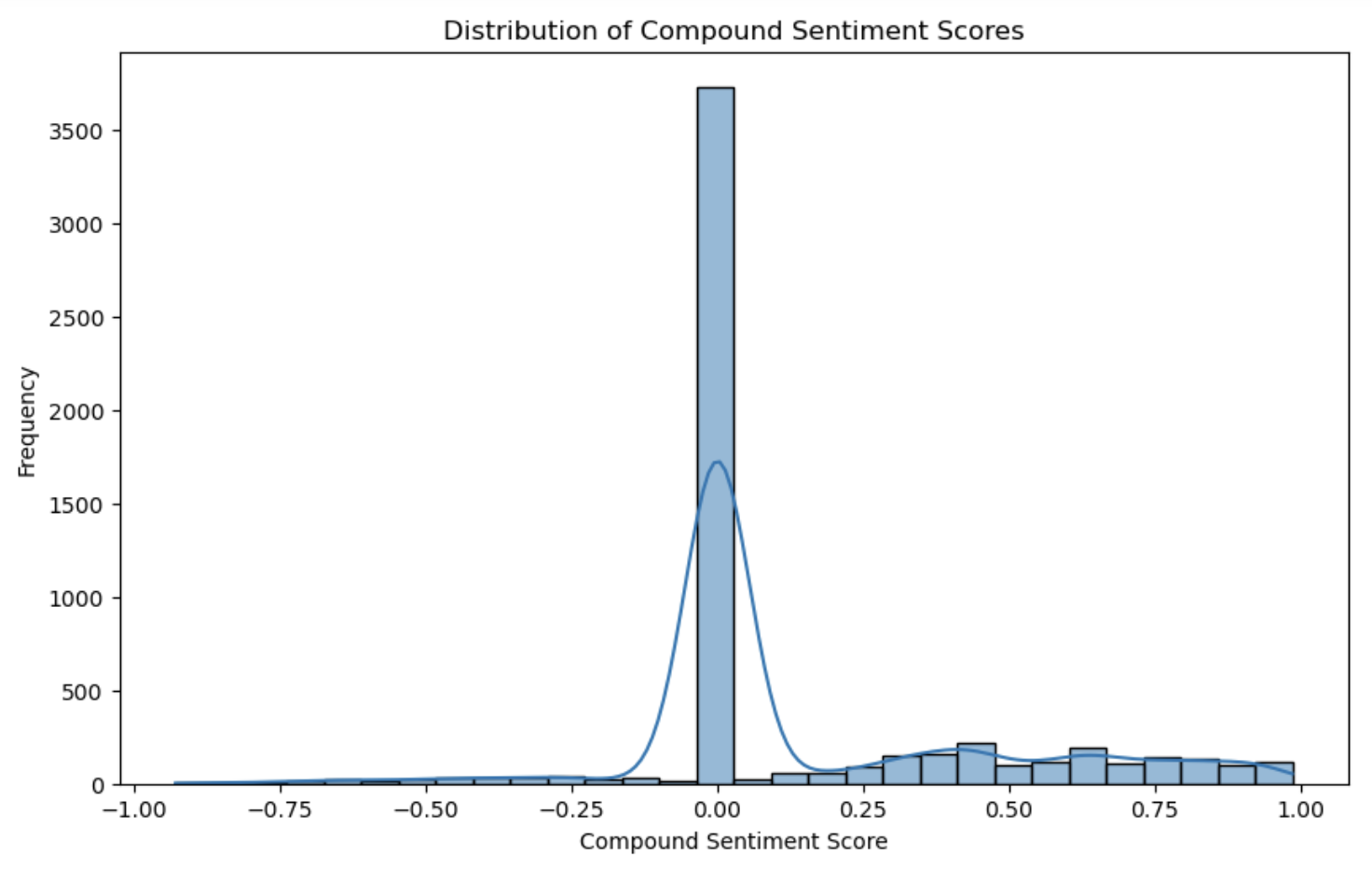
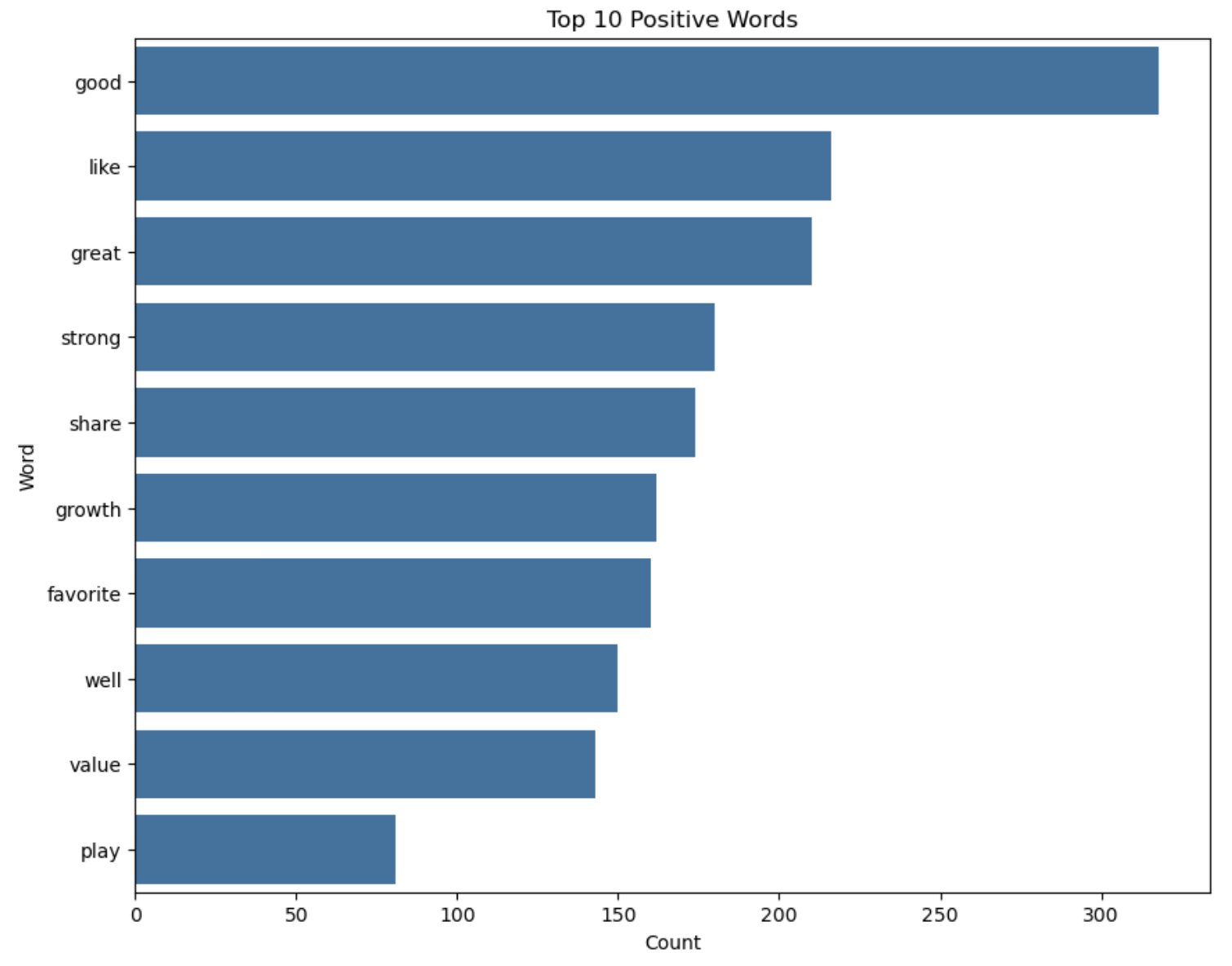
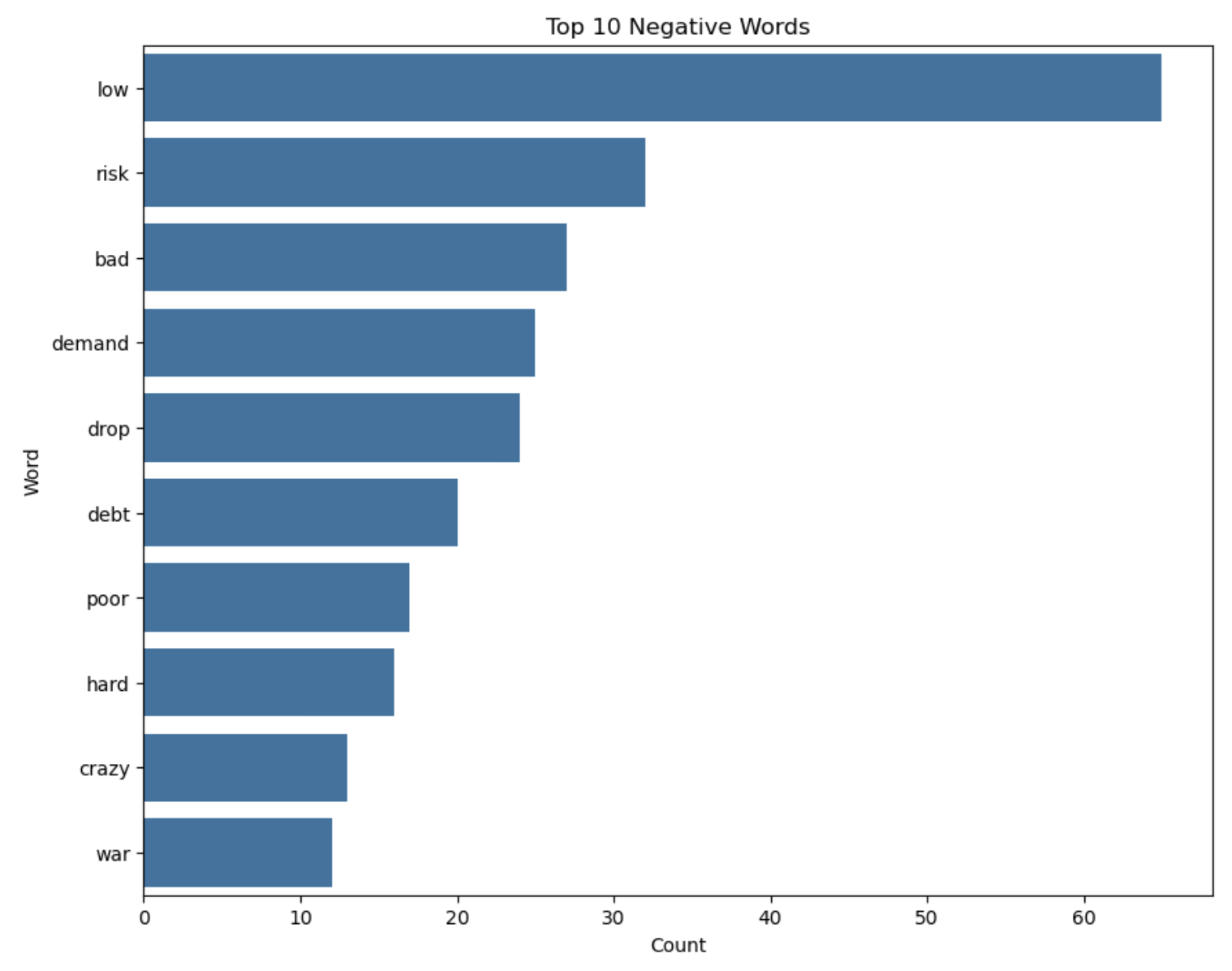
Part IV: Feature Engineering
Combining Features
# Getting the features of TF-IDF
tfidf_vectorizer = TfidfVectorizer(stop_words='english')
tfidf_features = tfidf_vectorizer.fit_transform(votingEventdf['text_no_stop_joined'])
# Getting the features of sentiment analysis
sentiment_features = votingEventdf[['compound', 'neg', 'neu', 'pos']].values
# Getting the features of LDA Model
lda_features = gensim.matutils.corpus2dense([lda_model[corpus[i]] for i in range(len(corpus))], lda_model.num_topics).T
# Combine the features in one matrix
combined_features = hstack([tfidf_features, sentiment_features, lda_features])
Clustering and Anomaly Detection
# Creating clusters
num_clusters = 3
kmeans = KMeans(n_clusters=num_clusters, random_state=42)
clusters = kmeans.fit_predict(combined_features)
# Add cluster labels to the dataframe
votingEventdf['cluster'] = clusters
# Isolation Forest for anomaly detection
isolation_forest = IsolationForest(contamination=0.1, random_state=42)
isolation_forest.fit(combined_features)
# Get anomaly scores
anomaly_scores = isolation_forest.decision_function(combined_features)
votingEventdf['anomaly_score'] = anomaly_scores
- Cluster 0: Contains shorter comments, possibly more casual and with some promotional links.”
- Cluster 1: Contains detailed, well-structured comments with substantial information and links, likely not SPAM.
- Cluster 2: Contains concise, positive comments about stocks, potentially more promotional but still relevant.
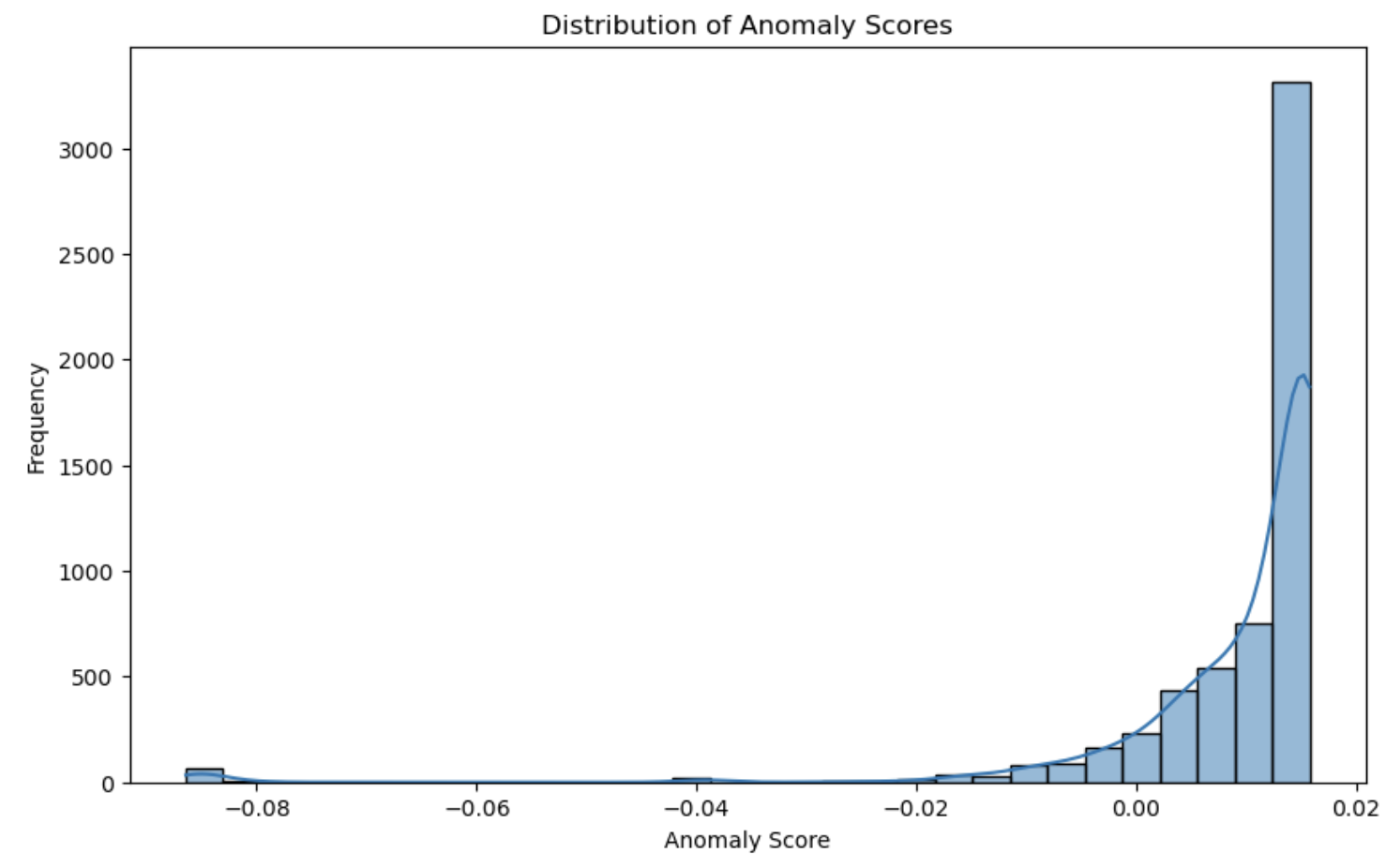
Labeling and Semi-Supervised Learning
# Sampled manual labels
manual_labels = {
657: 1, 18855: 0, 5891: 0, 1610: 1, 10865: 0, 17482: 0,
# ... (additional labels)
}
# Add 'is_spam' column to DataFrame
votingEventdf['is_spam'] = votingEventdf.index.map(manual_labels)
# Semi-Supervised Learning
X = combined_features
y = votingEventdf['is_spam'].values
y_unlabeled = np.copy(y)
y_unlabeled[np.isnan(y)] = -1
label_spreading = LabelSpreading(kernel='knn', n_neighbors=7)
label_spreading.fit(X, y_unlabeled)
votingEventdf['semi_supervised_is_spam'] = label_spreading.transduction_
# Anomaly Detection
isolation_forest.fit(X)
votingEventdf['anomaly_is_spam'] = isolation_forest.predict(X) == -1
votingEventdf['final_is_spam'] = votingEventdf[['semi_supervised_is_spam', 'anomaly_is_spam']].max(axis=1)
Part V: Model Development
Logistic Regression, Random Forest, SVM, Gradient Boosting
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(combined_features, votingEventdf['semi_supervised_is_spam'].values, test_size=0.2, random_state=42)
# Apply SMOTE to oversample the minority class
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)
# Define models
models = {
'Logistic Regression': LogisticRegression(random_state=42, class_weight='balanced', max_iter=1000),
'Random Forest': RandomForestClassifier(random_state=42, class_weight='balanced'),
'SVM': SVC(probability=True, random_state=42, class_weight='balanced'),
'Gradient Boosting': GradientBoostingClassifier(random_state=42)
}
# Initialize a dictionary to store results
results = {}
# Train and evaluate each model
for model_name, model in models.items():
# Train the model
model.fit(X_resampled, y_resampled)
# Predictions
y_pred = model.predict(X)
y_prob = model.predict_proba(X)[:, 1]
# Calculate metrics
accuracy = accuracy_score(y, y_pred)
auc = roc_auc_score(y, y_prob)
gini = 2 * auc - 1
report = classification_report(y, y_pred, output_dict=True)
# Store results
results[model_name] = {
'Accuracy': accuracy,
'AUC': auc,
'Gini': gini,
'Classification Report': report
}
# Display results
for model_name, metrics in results.items():
print(f"Model: {model_name}")
print(f"Accuracy: {metrics['Accuracy']}")
print(f"AUC: {metrics['AUC']}")
print(f"Gini Coefficient: {metrics['Gini']}")
print("Classification Report:")
print(metrics['Classification Report'])
print("\n")

Best Model: Random Forest
# Random Forest Model
X = combined_features
y = votingEventdf['semi_supervised_is_spam'].values
# Train-test split
X_train, X_test, y_train, y_test, train_idx, test_idx = train_test_split(X, y, votingEventdf.index, test_size=0.2, random_state=42)
# Apply SMOTE to oversample the minority class
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)
# Train the Random Forest model
random_forest = RandomForestClassifier(random_state=42, class_weight='balanced')
random_forest.fit(X_resampled, y_resampled)
# Predictions
y_pred = random_forest.predict(X_test)
y_prob = random_forest.predict_proba(X_test)[:, 1]
# Calculate metrics
accuracy = accuracy_score(y_test, y_pred)
auc = roc_auc_score(y_test, y_prob)
gini = 2 * auc - 1
report = classification_report(y_test, y_pred, output_dict=True)
# Display results
print("Random Forest Model")
print(f"Accuracy: {accuracy}")
print(f"AUC: {auc}")
print(f"Gini Coefficient: {gini}")
print("Classification Report:")
print(report)
print("\n")
# Filter comments predicted as SPAM
spam_comments = votingEventdf.loc[test_idx][y_pred == 1]['text']
# Print a sample of SPAM comments
print("Sample of Comments Predicted as SPAM by Random Forest:")
print(spam_comments.sample(10, random_state=42).values)
Saving Models
# Save the trained models
joblib.dump(random_forest, 'random_forest_model.pkl')
joblib.dump(tfidf_vectorizer, 'tfidf_vectorizer.pkl')
joblib.dump(lda_model, 'lda_model.pkl')
joblib.dump(dictionary, 'dictionary.pkl')
# Save other models
logistic_regression = LogisticRegression()
svm = SVC(probability=True)
gradient_boosting = GradientBoostingClassifier()
logistic_regression.fit(X_train, y_train)
svm.fit(X_train, y_train)
gradient_boosting.fit(X_train, y_train)
joblib.dump(logistic_regression, 'logistic_regression_model.pkl')
joblib.dump(svm, 'svm_model.pkl')
joblib.dump(gradient_boosting, 'gradient_boosting_model.pkl')
Part VI: Improving Model with BERT
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import Trainer, TrainingArguments
import torch
# Load the tokenizer and model
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
class SpamDataset(torch.utils.data.Dataset):
def __init__(self, texts, labels, tokenizer, max_len):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_len = max_len
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
label = self.labels[idx]
encoding = self.tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=self.max_len,
return_token_type_ids=False,
pad_to_max_length=True,
return_attention_mask=True,
return_tensors='pt',
)
return {
'text': text,
'input_ids': encoding['input_ids'].flatten(),
'attention_mask': encoding['attention_mask'].flatten(),
'labels': torch.tensor(label, dtype=torch.long)
}
# Prepare the dataset
max_len = 128
texts = votingEventdf['text'].tolist()
labels = votingEventdf['semi_supervised_is_spam'].tolist()
train_texts, val_texts, train_labels, val_labels = train_test_split(texts, labels, test_size=0.2)
train_dataset = SpamDataset(train_texts, train_labels, tokenizer, max_len)
val_dataset = SpamDataset(val_texts, val_labels, tokenizer, max_len)
# Training
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=1,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
warmup_steps=500,
weight_decay=0.01,
logging_dir='./logs',
logging_steps=10,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset
)
trainer.train()
trainer.evaluate()
BERT Prediction Function
def predict_spam_bert(text, model, tokenizer, max_len, device, threshold=0.5):
encoding = tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=max_len,
return_token_type_ids=False,
pad_to_max_length=True,
return_attention_mask=True,
return_tensors='pt',
)
input_ids = encoding['input_ids'].to(device)
attention_mask = encoding['attention_mask'].to(device)
model.to(device)
model.eval()
with torch.no_grad():
outputs = model(input_ids, attention_mask=attention_mask)
probabilities = torch.softmax(outputs.logits, dim=1)
spam_prob = probabilities[0][1].item()
is_spam = spam_prob >= threshold
return is_spam, spam_prob
# Example usage
text = "This is a demo text to check for SPAM."
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
max_len = 128
threshold = 0.5
is_spam, prob = predict_spam_bert(text, model, tokenizer, max_len, device, threshold)
print(f"Prediction: {'SPAM' if is_spam else 'Not SPAM'}, Probability: {prob}")
Part VII: API Deployment
Creating and Deploying the API
# Create a Flask application for model inference
app = Flask(__name__)
# Load models
random_forest = joblib.load('random_forest_model.pkl')
tfidf_vectorizer = joblib.load('tfidf_vectorizer.pkl')
lda_model = joblib.load('lda_model.pkl')
dictionary = joblib.load('dictionary.pkl')
bert_tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
bert_model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
def preprocess_text(text):
text = text.lower()
text = re.sub(r'[^\w\s]', '', text)
tokens = word_tokenize(text)
stop_words = set(stopwords.words('english'))
additional_stop_words = {'liking', 'pick', 'quickadded'}
tokens = [word for word in tokens if word not in stop_words and word not in additional_stop_words]
return ' '.join(tokens)
def transform_text(text):
text_preprocessed = preprocess_text(text)
tfidf_features = tfidf_vectorizer.transform([text_preprocessed])
text_tokens = text_preprocessed.split()
text_bow = dictionary.doc2bow(text_tokens)
lda_features = np.array([dict(lda_model[text_bow]).get(i, 0) for i in range(lda_model.num_topics)]).reshape(1, -1)
sentiment_features = np.array([sentiment_analyzer.polarity_scores(text_preprocessed)[key] for key in ['compound', 'neg', 'neu', 'pos']]).reshape(1, -1)
combined_features = np.hstack([tfidf_features.toarray(), sentiment_features, lda_features])
return combined_features
def predict_spam(text, model):
features = transform_text(text)
prediction = model.predict(features)
probability = model.predict_proba(features)
return prediction[0], probability[0][1]
def predict_spam_bert(text, model, tokenizer, max_len, device, threshold=0.5):
encoding = tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=max_len,
return_token_type_ids=False,
pad_to_max_length=True,
return_attention_mask=True,
return_tensors='pt',
)
input_ids = encoding['input_ids'].to(device)
attention_mask = encoding['attention_mask'].to(device)
model.to(device)
model.eval()
with torch.no_grad():
outputs = model(input_ids, attention_mask=attention_mask)
probabilities = torch.softmax(outputs.logits, dim=1)
spam_prob = probabilities[0][1].item()
is_spam = spam_prob >= threshold
return is_spam, spam_prob
@app.route('/predict', methods=['POST'])
def predict():
data = request.json
text = data['text']
rf_prediction, rf_probability = predict_spam(text, random_forest)
lr_prediction, lr_probability = predict_spam(text, logistic_regression)
svm_prediction, svm_probability = predict_spam(text, svm)
gb_prediction, gb_probability = predict_spam(text, gradient_boosting)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
bert_prediction, bert_probability = predict_spam_bert(text, bert_model, bert_tokenizer, 128, device)
response = {
'Random Forest': {'prediction': 'SPAM' if rf_prediction == 1 else 'Not SPAM', 'probability': rf_probability},
'Logistic Regression': {'prediction': 'SPAM' if lr_prediction == 1 else 'Not SPAM', 'probability': lr_probability},
'SVM': {'prediction': 'SPAM' if svm_prediction == 1 else 'Not SPAM', 'probability': svm_probability},
'Gradient Boosting': {'prediction': 'SPAM' if gb_prediction == 1 else 'Not SPAM', 'probability': gb_probability},
'BERT': {'prediction': 'SPAM' if bert_prediction else 'Not SPAM', 'probability': bert_probability}
}
return jsonify(response)
if __name__ == '__main__':
app.run(debug=True)
Running the API
To run the API, we saved the above code in a Python file (e.g., main.py) and run it using the command:
python main.py
We can then send POST requests to the /predict endpoint with the text we want to classify as spam or not spam.
API Cloud Deployment Summary
To deploy the spam detection API developed during my internship, I followed a structured approach to ensure a robust and scalable solution. Here’s a summary of the process:
-
Setup AWS EC2 Instance: I launched an EC2 instance using Ubuntu 24.04 LTS. This involved configuring security groups to allow SSH, HTTP, and custom TCP port 8000 access.
-
Connect and Configure the Instance: After connecting to the EC2 instance via SSH, I updated the package lists and installed necessary dependencies including Python 3.11, pip, and essential development tools.
-
Project Setup: I transferred the project files to the EC2 instance and set up a Python virtual environment. This isolated the project dependencies and ensured a clean runtime environment.
-
Dependency Installation: Inside the virtual environment, I installed all required Python packages as specified in the
requirements.txtfile, ensuring that the environment was fully prepared for running the application. -
Run the Uvicorn Server: I started the Uvicorn server to serve the FastAPI application, making the API accessible over the internet. This allowed for real-time interaction and testing of the spam detection functionality.
By following these steps, I successfully deployed the spam detection API on an AWS EC2 instance, making it accessible for further development, testing, and integration with the Fintech platform.
Conclusion
Our spam detection model utilizes a combination of traditional machine learning models and state-of-the-art deep learning models to effectively classify text as spam or not spam. We implemented the model using Python and various data science libraries, and deployed it as a Flask API. The system will enhance user experience, improve content quality, and increase operational efficiency on the Fintech platform.
Future Work
Future improvements could include:
- Further tuning and optimization of models.
- Incorporation of additional features and data sources.
- Implementation of more advanced deep learning architectures.
- Continuous monitoring and updating of models with new data.